
本記事はGMO AI&ロボティクス商事株式会社の技術検証に基づいています。
検証日: 2026年4月時点 / Kimodo v1.0.0
この記事でわかること
- Kimodoとは何か — NVIDIAが開発したテキスト→モーション拡散モデルの概要
- Unitree G1向けのセットアップ方法 — uvを使った環境構築からモーション生成まで
- 8種類のプロンプトによる生成結果 — 歩行・ダンス・ジェスチャーなど実際の出力
- トラブルシューティング — よくあるエラーと対処法
Kimodoとは — NVIDIAのテキスト→モーション拡散モデル
Kimodoは、NVIDIAのSpatial Intelligence Labが開発したキネマティック・モーション拡散モデルです。テキストプロンプトやキネマティック制約を通じて、高品質な3D人体・ロボットモーションを生成できます。
700時間の光学モーションキャプチャデータで学習されており、歩行・ダンス・物体操作・ジェスチャーなど多様な動作をテキスト指示から生成します。
モデルアーキテクチャ
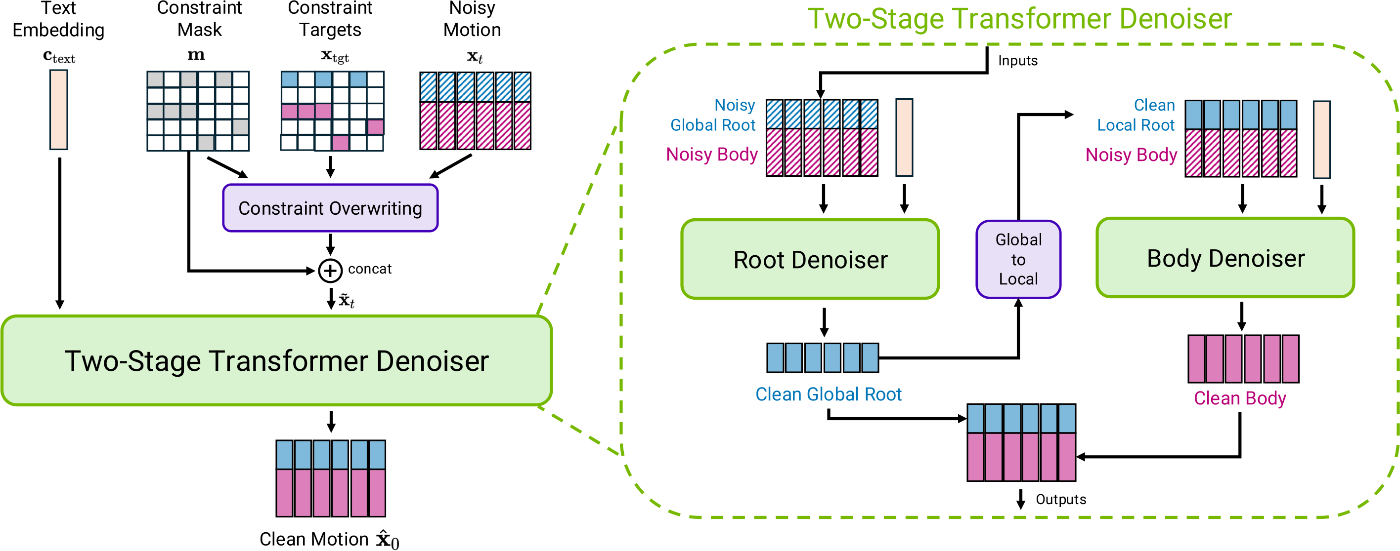
対応スケルトン:
- SOMA(デジタルヒューマン向け)
- Unitree G1(ヒューマノイドロボット向け)
- SMPL-X
主な制御機能:
- テキストプロンプトによるモーション生成
- フルボディキーフレーム制約
- エンドエフェクタ制約(手足の位置指定)
- 2Dウェイポイントやパスによるルートモーション制御
公式ページ: https://research.nvidia.com/labs/sil/projects/kimodo/
検証環境
項目 | 値 |
|---|---|
GPU | GeForce RTX 5090 |
OS | Ubuntu 22.04 |
CUDA | 12.8 |
Kimodo | v1.0.0 |
Kimodoはテキスト埋め込みモデルのサイズにより約17GBのVRAMが必要です。このうち大部分はテキストエンコーダ(meta-llama/Meta-Llama-3-8B-InstructベースのLLM2Vec)が占めます。モーション拡散モデル自体は軽量ですが、エンコーダが8Bパラメータのため16GB以下のGPUでは動作しません。RTX 5090(32GB VRAM)であれば余裕をもって動作します。
uvを採用した理由: pipやcondaと比べて仮想環境の作成とパッケージ解決が高速で、Pythonバージョンの固定もuv python pinで簡潔に行えるためです。
使用モデル
本記事ではKimodo-G1-RP-v1を使用します。Unitree G1ヒューマノイドロボットのスケルトンに対応し、700時間のモーションキャプチャデータ(Bones Rigplay 1)で学習されたモデルです。
全モデル一覧
モデル名 | スケルトン | 学習データ | 適用シーン | ライセンス |
|---|---|---|---|---|
Kimodo-G1-RP-v1 | Unitree G1 | Bones Rigplay 1(700時間) | ヒューマノイドロボットのモーション生成 | NVIDIA Open Model |
Kimodo-G1-SEED-v1 | Unitree G1 | BONES-SEED(288時間) | 軽量な基本動作の生成 | NVIDIA Open Model |
Kimodo-SOMA-RP-v1 | SOMA | Bones Rigplay 1(700時間) | デジタルヒューマン・アニメーション | NVIDIA Open Model |
Kimodo-SOMA-SEED-v1 | SOMA | BONES-SEED(288時間) | 軽量な基本動作の生成 | NVIDIA Open Model |
Kimodo-SMPLX-RP-v1 | SMPL-X | Bones Rigplay 1(700時間) | 人体モーション研究・VR/AR | NVIDIA R&D Model |
全モデルはHugging Faceから取得できます。モデルは初回実行時に自動ダウンロードされるため、手動でのダウンロードは不要です。
ライセンスについて: コードベースはApache-2.0ライセンスですが、モデルチェックポイントは別ライセンスです。G1/SOMA系モデルはNVIDIA Open Model Licenseで研究・商用利用ともに許可されています。SMPLX-RP-v1のみNVIDIA R&D Model License(研究用途限定)となります。詳細は各Hugging Faceページのライセンス表記を確認してください。
インストール手順
前提条件:Hugging Faceトークンの設定
Kimodoのテキストエンコーダはmeta-llama/Meta-Llama-3-8B-Instruct(ゲートモデル)に依存しています。事前に以下の準備が必要です。
1. Llama 3モデルへのアクセス申請
meta-llama/Meta-Llama-3-8B-Instructのページからアクセスをリクエストし、承認を受けてください。
2. アクセストークンの作成
Hugging Faceのトークン作成ページでReadトークンを発行します。
3. CLIでログイン
pip install --upgrade huggingface_hub
huggingface-cli loginまたは、トークンを直接 ~/.cache/huggingface/token に書き込む方法でも認証可能です。
uvで環境構築
リポジトリをクローンし、uvでPython 3.10の仮想環境を作成します。
# uvのインストール(未導入の場合)
curl -LsSf https://astral.sh/uv/install.sh | sh
# リポジトリのクローン
git clone https://github.com/nv-tlabs/kimodo.git
cd kimodo
# Python 3.10を指定して仮想環境を作成・有効化
uv python pin 3.10
uv venv
source .venv/bin/activatePyTorchのインストール
PyTorch 2.0以上が必要です。CUDA 12.8に対応したバージョンを先にインストールします。
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128PyTorchのインストールコマンドは https://pytorch.org/get-started/locally/ で環境に合わせて確認してください。
Kimodoのインストール
ローカルのリポジトリからeditableモードでインストールします。
# 基本インストール
uv pip install -e .
# インタラクティブデモも使う場合(推奨)
uv pip install -e ".[all]"kimodo-viserのインストール
インタラクティブデモで使用するビジュアライザです。別リポジトリとしてクローンし、インストールします。
git clone https://github.com/nv-tlabs/kimodo-viser.git
uv pip install -e kimodo-viserモーション生成を実行する
テキストエンコーダサービスの起動
モーション生成はテキストプロンプトの埋め込みに依存しています。CLIやデモを単独で実行しても動作しますが、テキストエンコーダサービスをバックグラウンドで常駐させるほうが効率的です。連続して複数のCLI呼び出しを行う場合、毎回テキストエンコーダを初期化する必要がなくなります。
# 別ターミナルで実行(バックグラウンド常駐させる)
kimodo_textencoder初回実行時は埋め込みモデルのダウンロードに時間がかかります。
テキストエンコーダの初期化時に、transformersライブラリがLLM2Vecの予期しないレイヤーや不足レイヤーについて警告を出しますが、これは想定内の挙動なので無視して問題ありません。
CLIでモーション生成
kimodo_gen "A person walks forward." \
--model Kimodo-G1-RP-v1 \
--duration 5.0 \
--output output出力ファイル
kimodo_genを実行すると、以下のファイルが出力されます。
Unitree G1スケルトン(Kimodo-G1-RP-v1)ではNPZとCSV形式で出力されます。BVHエクスポートはSOMAスケルトンのみ対応しています。
ファイル | 形式 | サイズ目安 | 説明 |
|---|---|---|---|
output.npz | NPZ | 〜256KB〜680KB | モーションデータ(NumPy圧縮形式、関節角度・位置を含む) |
output.csv | CSV | 〜81KB〜216KB | モーションデータ(CSV形式、各フレームの関節値) |
出力ファイルのサイズはモーションの長さ(duration)に比例します。例えば3秒のモーションで約256KB(NPZ)、8秒で約680KB(NPZ)です。
実行例(テキストエンコーダサービス常駐時):
$ kimodo_gen "A person walks forward." --model Kimodo-G1-RP-v1 --duration 5.0 --output output
Using device: cuda:0
Loaded model: Kimodo-G1-RP-v1 (kimodo-g1-rp)
Will generate motions with the following prompts
'A person walks forward.' with 150 frames
100%|██████████| 100/100 [00:02<00:00, 37.71it/s]
Saving the npz output to output.npz
Saving the csv output to output.csvプロンプト例と生成結果
以下のプロンプトでモーション生成を試しました。テキストエンコーダサービスを常駐させた状態では、モデルキャッシュ後の生成時間は各プロンプト約7〜9秒でした。
プロンプト | duration | 出力サイズ (NPZ) | 生成時間 | 備考 |
|---|---|---|---|---|
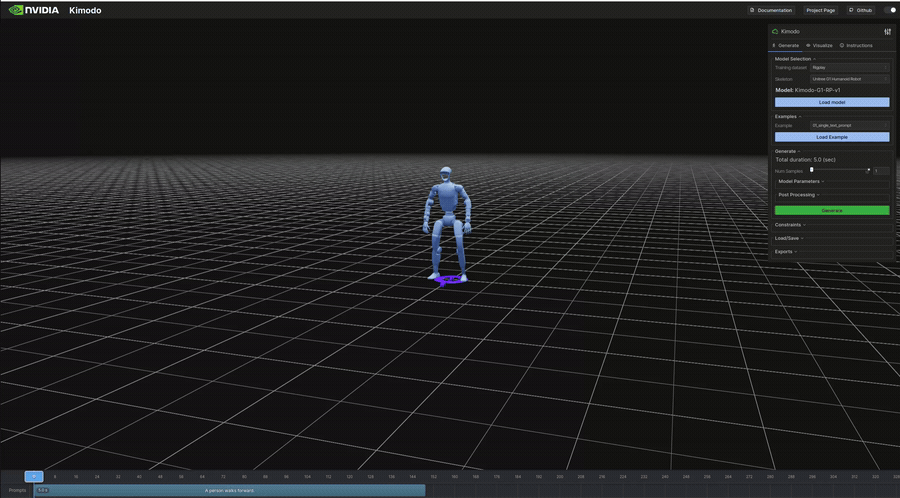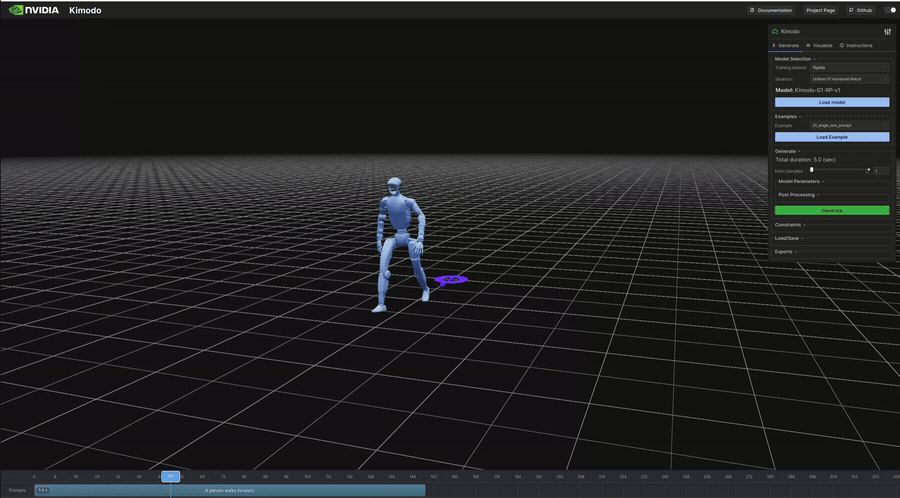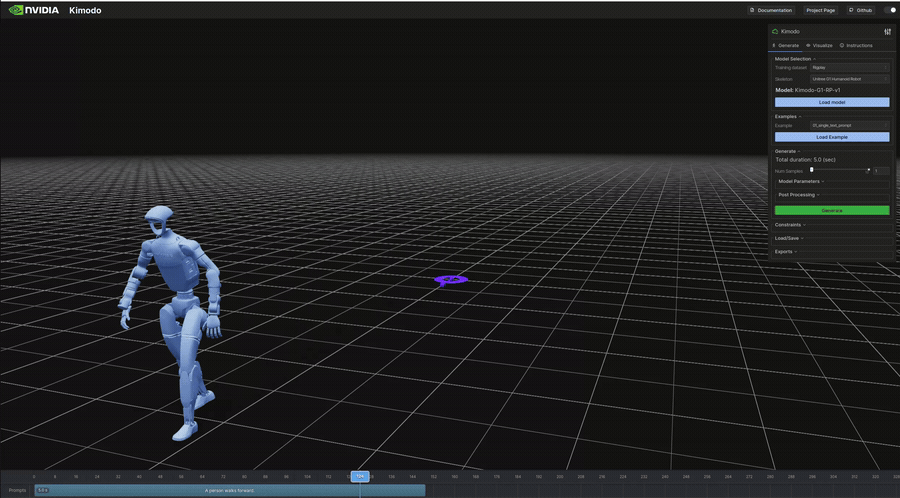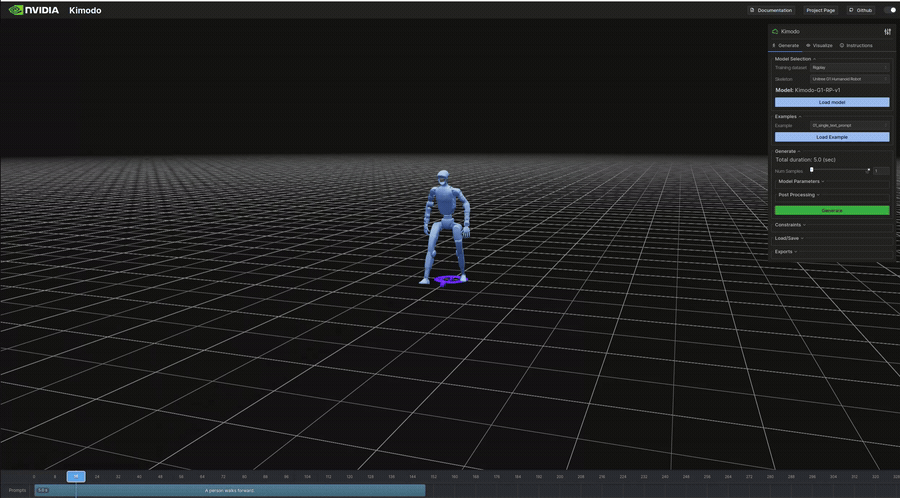
"A person walks forward." | 5.0s | 426KB | 7s | 基本的な前方歩行。安定した歩行サイクルが生成された |
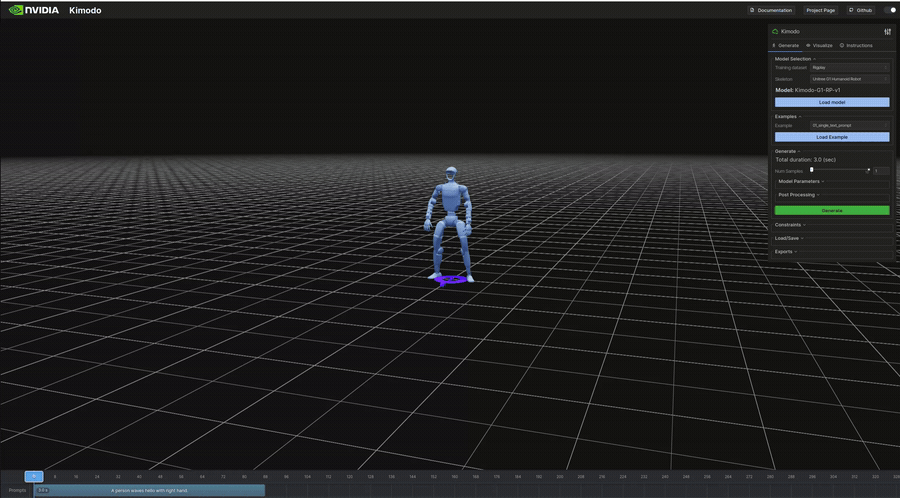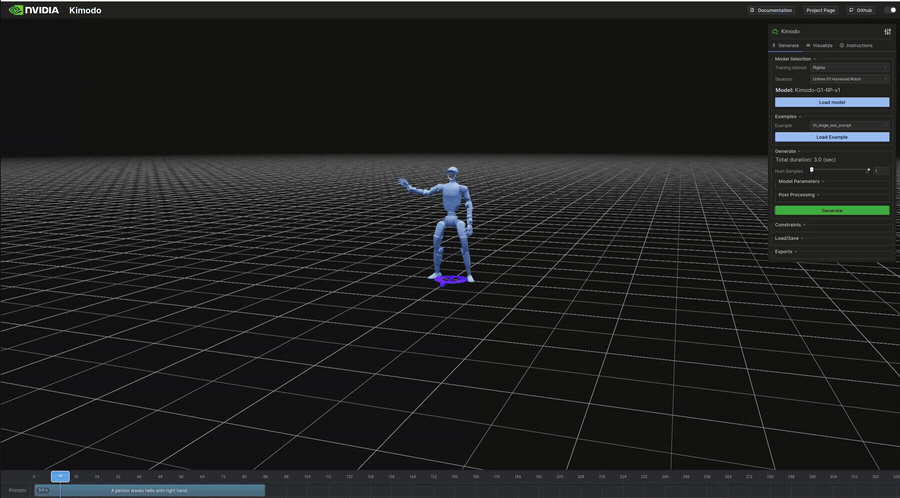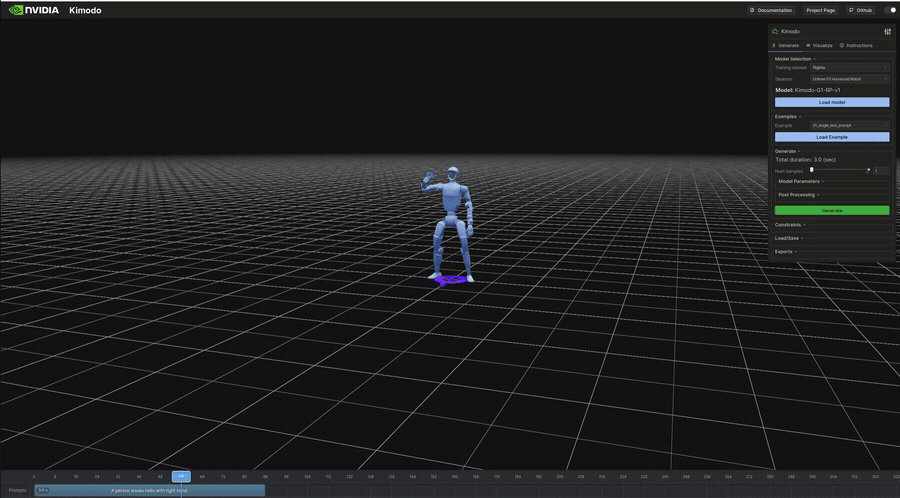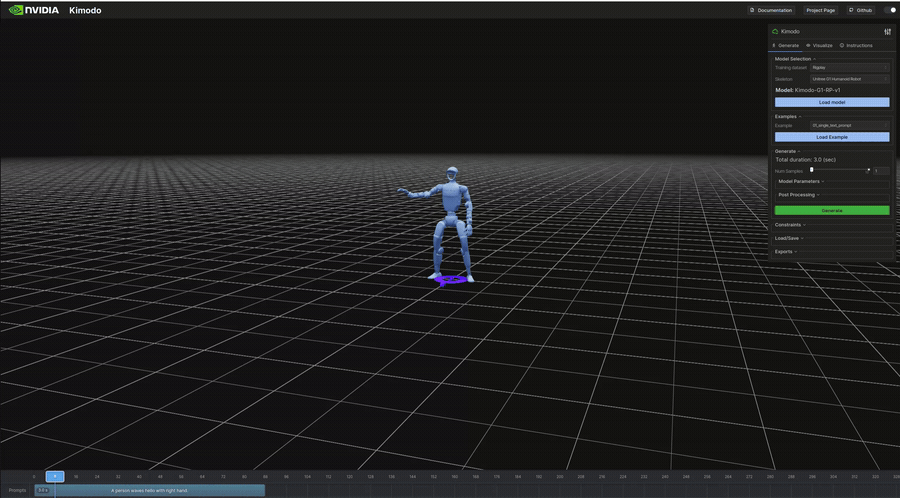
"A person waves hello with right hand." | 3.0s | 256KB | 7s | 右手を振る挨拶ジェスチャー。上半身の動作 |
"A person does a jumping jack." | 4.0s | 341KB | 7s | ジャンピングジャック。全身の協調動作 |
"A person picks up an object from the floor." | 5.0s | 426KB | 7s | かがんで物を拾う動作。物体操作系 |
"A person dances hip hop." | 8.0s | 680KB | 9s | ヒップホップダンス。長めのdurationで多様な動きが生成された |
"A robot stands up from sitting position." | 4.0s | 341KB | 7s | 座位から立ち上がり。ロボット向けの動作記述 |
"A person walks in a circle." | 6.0s | 511KB | 8s | 円を描く歩行。ルートモーション制御の確認 |
"A person kicks a ball with right foot." | 3.0s | 256KB | 7s | 右足でボールを蹴る動作。脚部の動き |
プロンプトは英語で記述します。日本語には対応していません。動作の具体性が高いほど生成品質が向上する傾向があります。初回実行時はモデルのダウンロードとキャッシュのため約2分かかりますが、2回目以降は7〜9秒で生成できます。
生成結果のビジュアル(抜粋)
以下は表のうち、ビジュアライザで再生したモーションのGIFです。
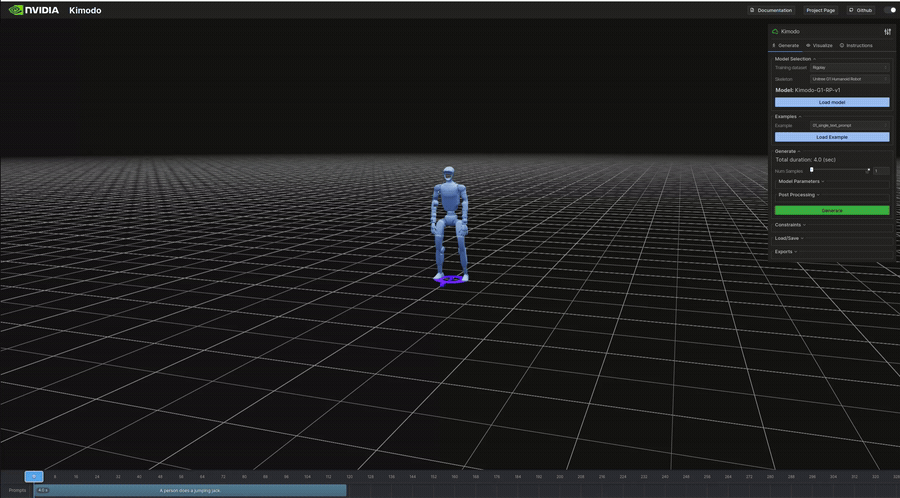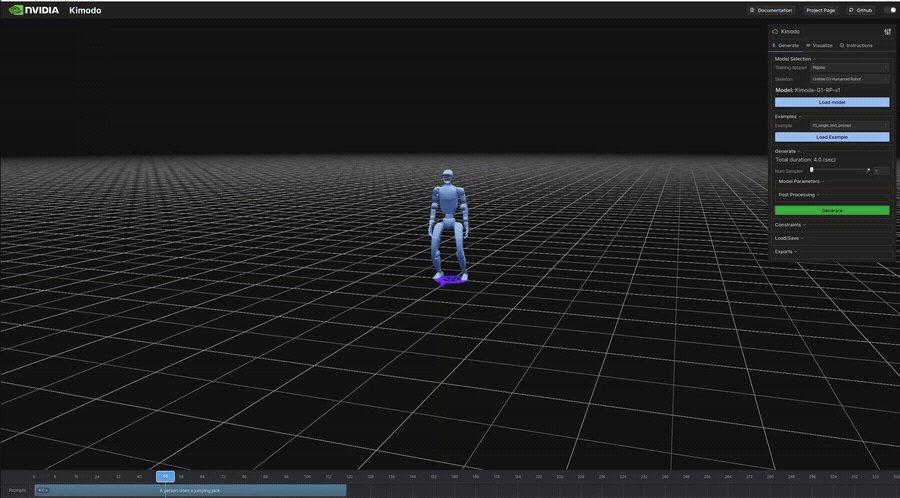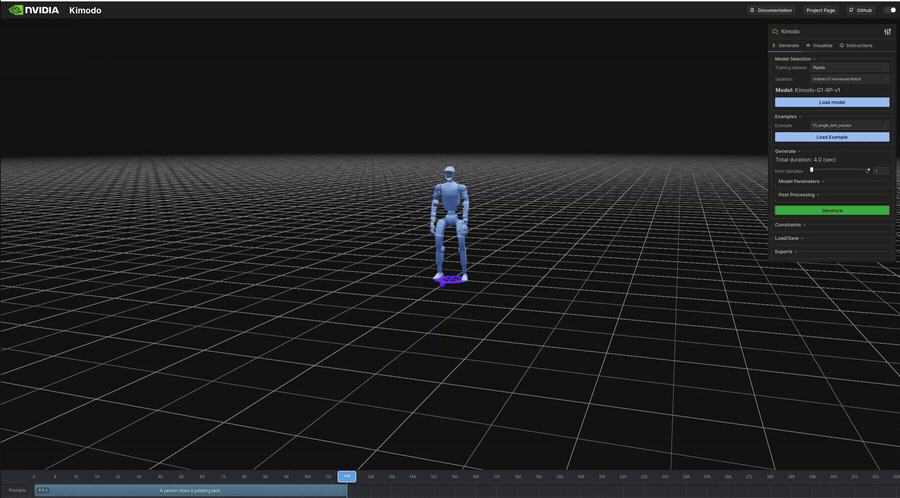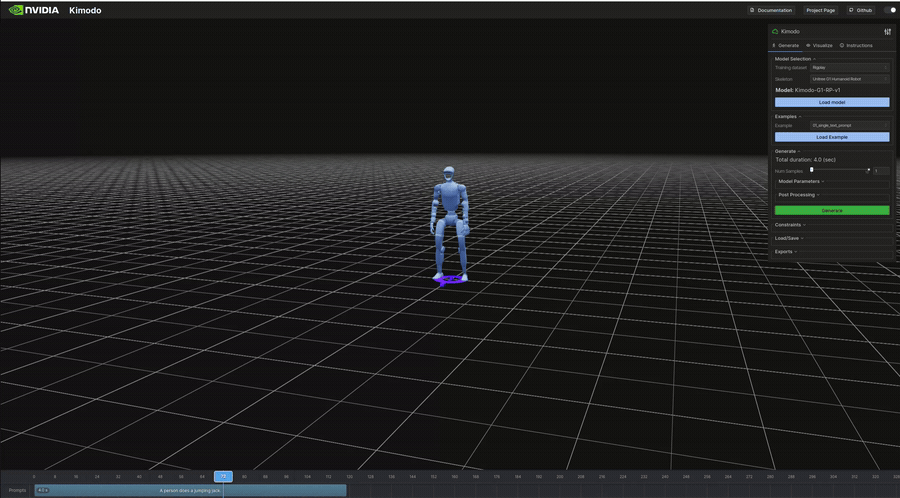
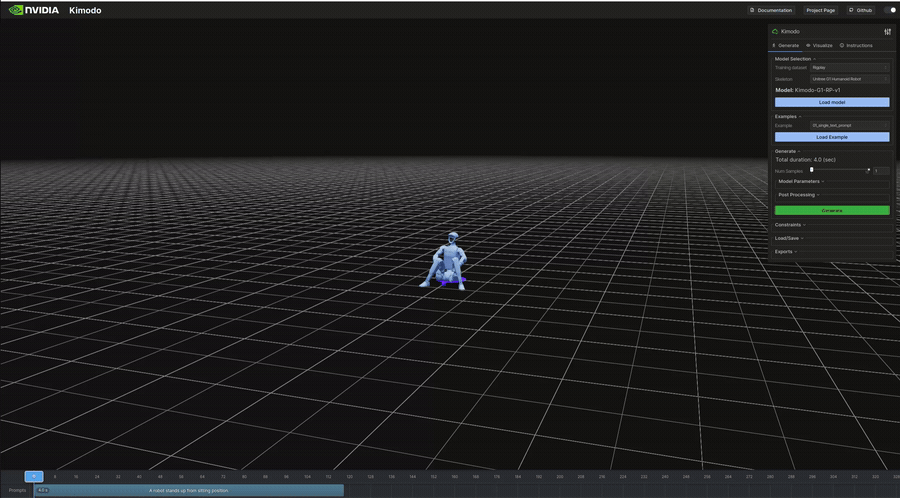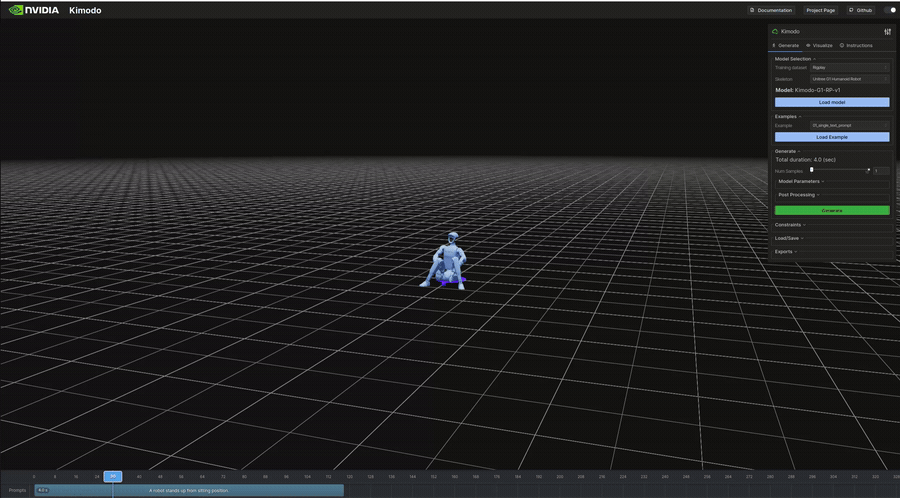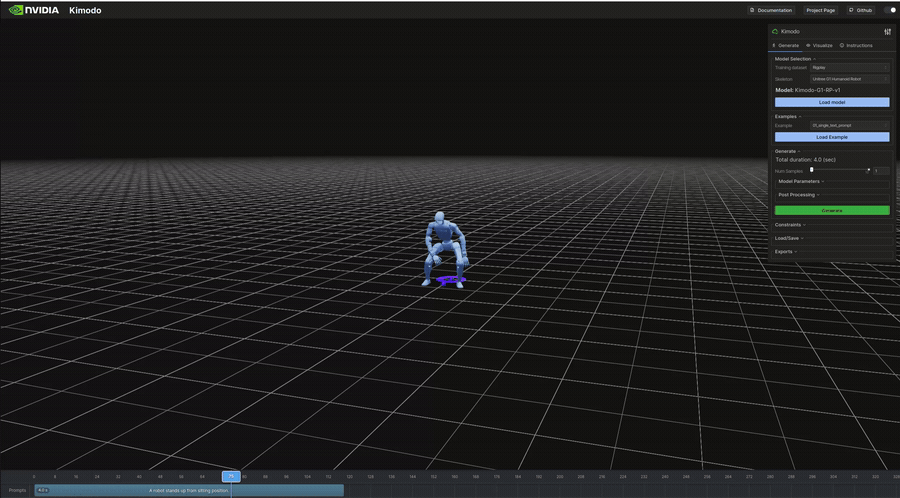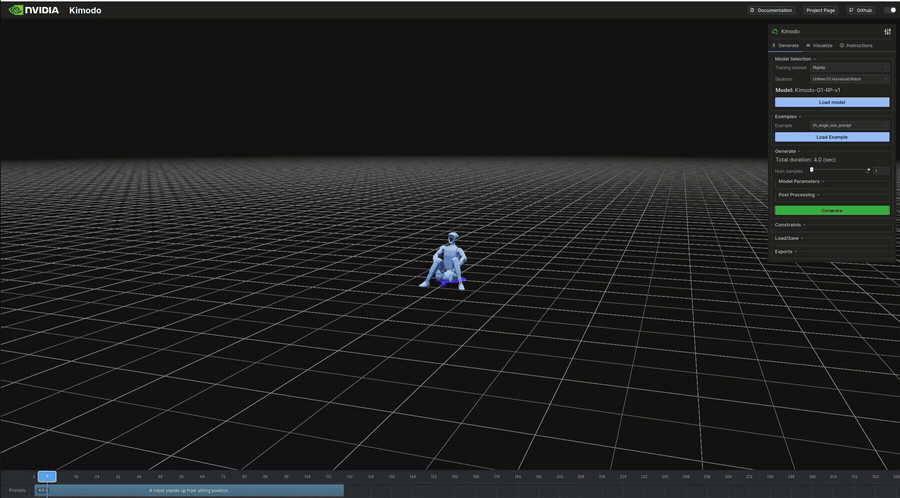
インタラクティブデモ
テキストプロンプトや制約を直感的にコントロールできるWebアプリケーションです。kimodo_demo
ブラウザで http://localhost:7860 を開くとインターフェースにアクセスできます。
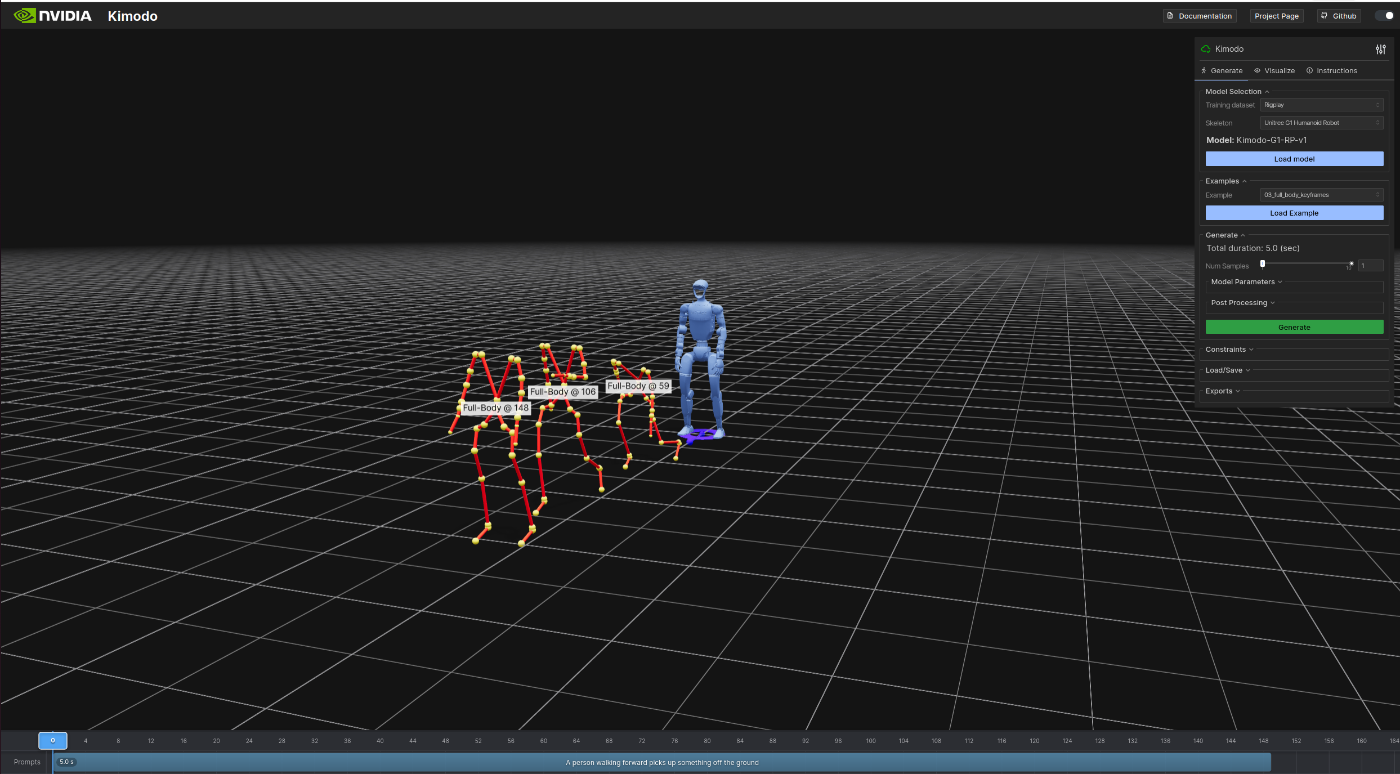
デモUIでは、タイムライン上でキーフレーム制約やエンドエフェクタ制約を視覚的に配置し、テキストプロンプトと組み合わせたモーション生成が可能です。
生成モーションの活用例
Kimodoで生成したモーションデータは、ロボティクスや3Dアニメーションのパイプラインに直接組み込めます。
NVIDIA Isaac Simとの連携
生成されたNPZファイルをIsaac Simにインポートすることで、Unitree G1のシミュレーション環境でモーションを再生・評価できます。強化学習のリファレンスモーションとして使用し、模倣学習(imitation learning)のベースラインとする活用が考えられます。
MuJoCoでの検証
NPZデータをMuJoCoのキーフレーム形式に変換すれば、物理シミュレーション上でモーションの実現可能性を検証できます。関節トルクや接触力の解析により、実機展開前の安全性評価に役立ちます。なお、kimodo_convertコマンドでNPZ/CSV/BVH間のフォーマット変換が可能です。
実機への展開
シミュレーションで検証したモーションをUnitree G1の実機にデプロイするワークフローも想定されています。Sim-to-Real転移の一環として、Kimodoで大量のモーションデータを生成し、ポリシー学習の訓練データとして活用するアプローチが有望です。
トラブルシューティング
Hugging Faceトークン未設定・Llama 3アクセス未承認
OSError: You are trying to access a gated repo.
このエラーが出た場合:
- Llama 3のモデルページでアクセスリクエストを送信し、承認メールを待つ
huggingface-cli loginでトークンを設定する- トークンにReadスコープが含まれていることを確認する
CUDAバージョン不一致
RuntimeError: CUDA error: no kernel image is available for execution on the device
PyTorchとCUDAのバージョンが一致していない場合に発生します。
# インストール済みのCUDAバージョンを確認
nvcc --version
# PyTorchが認識しているCUDAバージョンを確認
python -c "import torch; print(torch.version.cuda)"両者が一致していない場合、PyTorch公式から正しいバージョンのインストールコマンドを取得し、再インストールしてください。
LLM2Vecの警告メッセージ
テキストエンコーダ起動時に以下のような警告が表示されますが、動作に影響はありません。
Some weights of the model checkpoint were not used when initializing…
これはLLM2Vecが元のLlama 3モデルからファインチューニングされた際の構造差異によるもので、想定内の挙動です。
VRAM不足エラー
torch.cuda.OutOfMemoryError: CUDA out of memory.
16GB以下のGPUでは、テキストエンコーダ(Llama 3-8Bベース)だけで約14-15GBを消費するため動作しません。最低でも24GB VRAM(RTX 3090/4090以上)を推奨します。
まとめ
Kimodoの導入は以下の3ステップで完了します。
- Hugging Faceの設定 — Llama 3のアクセス承認とトークン発行
- 環境構築 — uvでのリポジトリクローン、PyTorch/Kimodo/kimodo-viserのインストール
- モーション生成 — テキストエンコーダサービスの起動後、CLIまたはデモで実行
RTX 5090環境では、インストールから最初のモーション生成まで約10分で完了しました(モデルの初回ダウンロード時間を除く)。テキストプロンプトの英語記述のみ対応ですが、動作の具体性を上げることで品質の高いモーションが生成できます。
現時点での制限として、リアルタイム生成には対応しておらず、テキストエンコーダサービス常駐時でも1回の生成に約7〜9秒を要します(拡散ステップ100回分)。また、Unitree G1スケルトン(Kimodo-G1-RP-v1)ではBVH形式での出力に対応しておらず、NPZ/CSV形式のみとなります。SOMAスケルトン用のモデルを使えばBVHエクスポートが可能です。歩行やジェスチャーには十分な品質のモーションが生成される一方、複雑な物体操作や環境とのインタラクションを伴う動作には改善の余地があります。
今後は、生成したモーションをIsaac SimやMuJoCoに取り込み、強化学習の訓練データとして活用する検証を進める予定です。テキスト指示だけで多様なモーションを生成できるKimodoは、ロボットのポリシー学習におけるデータ収集コストを大幅に削減できる可能性を持っています。
採用についてお知らせ
GMOインターネットグループ株式会社 グループ研究開発本部 AI研究開発室では,フィジカルAI・ロボティクスのリサーチエンジニア・リサーチサイエンティストを募集しています。ヒューマノイドの全身制御やその他の要素技術,社会実装にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
