
はじめに
強化学習で脚式ロボットに走り方を学ばせるとき、報酬として与えるのは多くの場合「指定した速度で前進できたか」「転倒しなかったか」といったタスクの達成度です。ところがこれだけを最適化すると、目標は満たすのに動作そのものは不自然で、関節が小刻みに振動するような挙動に収束しがちです。
動作を自然に近づけようとして、腕の振り・足の上げ方・着地の衝撃といった項目の報酬を個別に設計していくと、今度は項目間で目的が競合し、重み調整が際限なく続きます。
この問題に対する一つの答えが Adversarial Motion Priors(AMP)です。本記事では、二足歩行ロボット Unitree H1 に AMP で走行を学習させた際の考え方と、実装で押さえた点を整理します。実装はオープンソースの強化学習プロジェクト unitree_rl_mjlab(MuJoCo ベース)を土台に、H1 向けへ拡張したものです。
AMP とは何か
AMP は、お手本となるモーションデータに動作のスタイルを近づけるための手法です。考え方は画像生成で知られる GAN(敵対的生成ネットワーク)と共通しています。学習には二つの要素が登場します。
- 判別器(discriminator):与えられた動作の断片が、モーションデータ由来か、学習中の方策が生成したものかを見分けるニューラルネットワーク。
- 方策(policy):ロボットの制御器。判別器がモーションデータに近いと判定させるほど高い報酬(スタイル報酬)を得る。
判別器は両者を見分けられるように学習し、方策は判別器を欺けるように学習します。この相互作用を繰り返すと、方策はお手本に近い動作を獲得していきます。人が「自然さ」を数式で定義する必要はなく、参照したい動作のデータを用意すれば済む点が AMP の要点です。
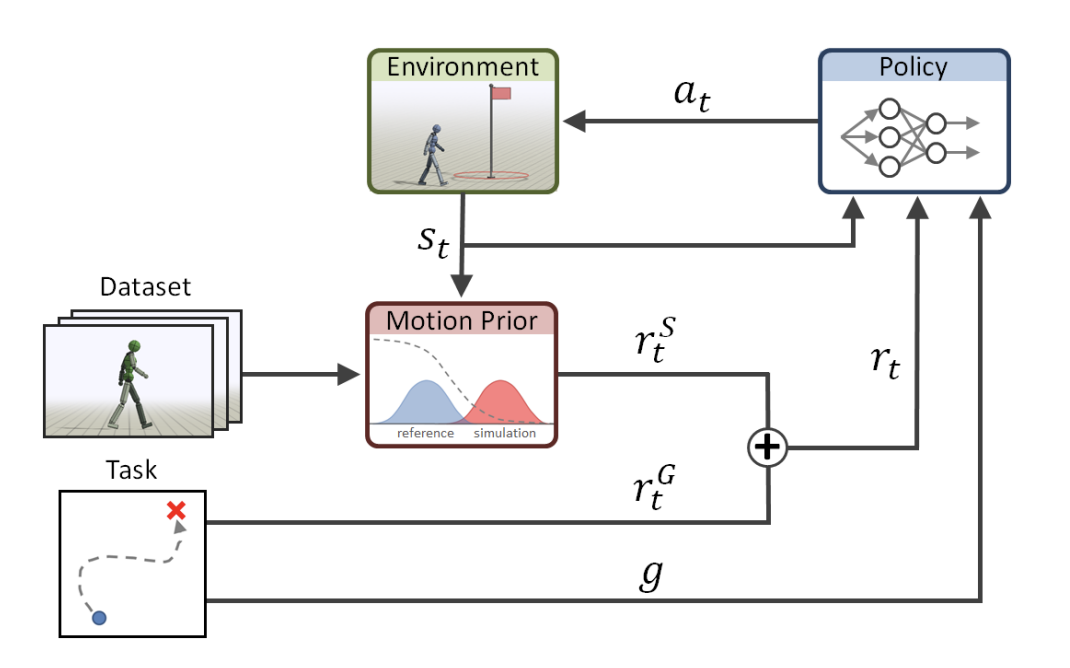
学習で用いる報酬は二種類です。一つは指定どおりの速度・方向で走れているかを評価するタスク報酬、もう一つはお手本らしく動けているかを評価するスタイル報酬です。最終的な報酬はこの二つの重み付き和として与えます。スタイル報酬は判別器の出力から計算され、モーションデータに近いと判定されたときに最大、外れるほど小さくなり、一定以上外れるとゼロになります。
重要なのは、学習アルゴリズムの本体が標準的な PPO のままだという点です。AMP が加えるのは、報酬の生成にスタイル報酬を組み込むことと、方策と並行して判別器を学習させることの二点が主なところです。この標準的なPPO側の報酬がタスク報酬というわけです。
もう一つ押さえておきたいのは、AMP が学習させるのは特定の一本のモーションを一コマずつなぞるようなフレーム単位の追従ではなく、モーションデータ群に共通する動きの「らしさ」、いわば全体の傾向だという点です。走る速度や向きの指示は、スタイルとは別系統の目標として方策に与えます。そのため指示を変えても、方策は学習したスタイルを保ったまま追従でき、動きの自然さ(AMP が担う部分)と、何をさせるか(タスクの指令)を切り分けて扱えます。
モーションのリターゲティング
モーションデータをどう取得するかについて説明しておきます。参照データとなるモーションは、人の動作計測データなど、ロボットとは異なる骨格の上で定義されていることがほとんどです。骨格が違う以上、関節角度をそのまま H1 に移しても破綻します。そこで、ある骨格の動作を別の身体(ここでは H1)の関節構成へ変換する処理が必要になります。これがモーションリターゲティングです。
今回はこの工程を自前で実装せず、オープンソースのリターゲティングツール GMR(General Motion Retargeting)を利用し、H1 向けに設定して使いました。GMR は逆運動学と最適化を用いて、関節の可動範囲などの制約を守りながら、元の姿勢を目標ロボットの姿勢へ写します。出力として、ベースの位置・姿勢と各関節の角度が得られます。
リターゲティングで得た動作は、AMP がそのまま扱える形式へ整えてから学習に渡します。整合させるべき点は次のとおりです。
- フレームレートを学習環境に合わせる。リターゲティング出力(60 fps)を、シミュレーションのステップレート(50 Hz)へリサンプリングする。こうすると、判別器が見る「1 ステップあたりの動きの変化量」が、学習中のロボットの観測と同じ時間幅になる。
- 速度を補う。元データに含まれない関節速度やベース速度を、位置の差分から計算して付与する。
- 表現を統一する。回転を表すクォータニオンの成分順など、シミュレーション側の規約に合わせる。
地味な前処理ですが、ここでの不整合は学習の破綻に直結するため、判別器が見るモーションデータと方策の観測が同じ表現に揃っていることを丁寧に確認します。
大規模並列シミュレーションで学習する
強化学習は膨大な試行錯誤を必要とします。そこでこの学習では、一体ずつ順番に動かすのではなく、GPU 上で多数の仮想ロボットを同時に走らせます。土台の unitree_rl_mjlab は、GPU 対応の MuJoCo を物理エンジンに用いる mjlab の上に構築されており、数千体規模(公開されている例では 4096 体)の環境を並列にシミュレーションできます。多くの試行を一度に進められるため、走行のような動的な動作でも現実的な時間で学習を回せます。
今回のH1 への実装で押さえた点
unitree_rl_mjlab をベースにしたAMPにはG1を使ったいくつかの実装例があります。これを元に H1 で動かす形で進めましたが、身体が異なると見直しが必要になる箇所が複数あります。
体格差に応じた再設定
H1 は G1 に比べて関節数が少なく(19 自由度に対し G1 は 29)、足首はピッチのみでロール軸を持たず、胴体も単一関節で手首がありません。一方で質量は G1 のおよそ 1.5 倍あり、背丈も高くなります。この違いは設定値に直接効きます。接地力の上限や消費電力の上限といった、身体の質量やモーター出力に比例する閾値は、H1 の諸元に合わせて取り直す必要があります。背が高いぶん、立位姿勢の目標高さも引き上げます。近縁機の値をそのまま流用すると成立しないため、身体に依存するパラメータを系統的に見直しました。
判別器に渡す観測の設計
判別器に渡すのは一瞬の姿勢ではなく、連続するフレーム、すなわち動きの遷移です。今回は二フレーム分を一組として扱います。各フレームの内容は、関節角度・関節速度・ベースの並進速度・重力方向です。重力方向を含めるのは、判別器が姿勢の傾き、つまりバランスの崩れまで評価できるようにするためです。
一方で、ベースの絶対位置や向きは判別器の観測に含めていません。スタイルは走っている場所や方角に依存しないため、これらを除くことで、位置や方位に左右されない動作の自然さそのものを評価できます。お手本側の観測も、関節角を基準姿勢からの差分として表すなど、方策側の観測と同じ表現に揃えています。
スタイル系の報酬を整理する
AMP を導入する実装上の利点として、自然さに関わる報酬を手作業で積み上げる必要が薄れることが挙げられます。姿勢・足の上げ方・着地の滑らかさ・腕の動きといったスタイルに関わる項目は判別器が担うため、従来は個別に設計していたこれらの報酬を整理し、削減できました。腕の動作については報酬の重みをゼロにして記録のみとし、自然な腕の振りは判別器に委ねています。結果として報酬設計が簡潔になり、項目間の競合に起因する調整の負担が軽くなります。タスクの達成度や安全に関わる報酬は引き続き明示的に与えます。
Reference State Initialization(RSI)
毎回静止姿勢から走り出すのは、学習にとって効率の悪い設定です。特に高速域の動作は、立位からの探索だけではなかなか到達できません。RSI では、エピソードのリセット時に一定の確率で、お手本の途中フレーム(その瞬間の関節姿勢と速度)をロボットの初期状態として与えます。走行の途中から学習を始められるため、到達しにくい状態の探索が容易になります。これは動作模倣の研究で広く使われてきた手法で、AMP とも相性のよい組み合わせです。
判別器の学習を安定させる
敵対的な学習では、判別器が方策よりも速く強くなりすぎると、方策が何をしても見分けられてしまい、学習の手がかりとなる勾配が失われます。これを避けるため、判別器の学習に次の抑制を加えています。
- 判別器の出力が入力に対して急峻になりすぎないよう、勾配へのペナルティと重みの正規化を併用する。
- 判別器の学習率を方策よりも低く(およそ十分の一に)設定し、先行して強くなりすぎないようにする。
外乱やばらつきに強くする(ドメインランダム化)
シミュレーションで学習したポリシーは、条件が少し変わるだけで崩れがちです。これを防ぐため、学習中はあえて条件をばらつかせます。走行中のロボットを不意に押して姿勢の立て直しを覚えさせ、足裏の摩擦や胴体の重心位置を試行ごとにランダムに変え、さらに方策が受け取るセンサ観測にノイズを加えます。多様で不確かな状況を経験させておくことで、特定の理想条件だけに最適化されない、崩れにくいポリシーが育ちます。なお価値推定を担う critic 側にはノイズを加えない非対称な構成とし、学習の安定とロバスト性を両立させています。これらはいずれも学習時のみ有効で、動作確認時には外乱やノイズを切って挙動を観察します。
難易度を段階的に上げる(カリキュラム)
最初から最高難度で学習させるのではなく、易しい条件から始めて段階的に難しくします。たとえば指令する速度の範囲は初めは狭くしておき、ポリシーがその範囲をこなせて転倒も十分に少ないと確認できてから、上限を少しずつ広げます。時間任せに上げるのではなく、達成度を見て次の段階へ進めるのがポイントです。旋回の範囲も同様に少しずつ広げ、押し外乱も学習の進行に合わせて強めていきます。易しいケースを先に固めてから難しいケースへ移ることで、学習が安定します。
まとめ
AMP は、自然さを人手で設計するという難しい問題を、お手本に似ているかをデータから評価するという形に置き換えます。H1 への実装では、身体の違いに応じたパラメータの取り直し、スタイル系報酬の整理、お手本データのリターゲティングと形式の整合、RSI と判別器の安定化、そして外乱へのロバスト化と段階的なカリキュラムが要点になりました。
なお、今回の取り組みはシミュレーション上での学習を対象としています。実機での走行は今後の課題です。
参考
- X. B. Peng et al., “AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control,” SIGGRAPH 2021.
- X. B. Peng et al., “DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills,” SIGGRAPH 2018.(RSI の出典)
- General Motion Retargeting(GMR)
- unitree_rl_mjlab(mjlab / MuJoCo)
採用についてお知らせ
GMOインターネットグループ株式会社 グループ研究開発本部 AI研究開発室では,フィジカルAI・ロボティクスのリサーチエンジニア・リサーチサイエンティストを募集しています。ヒューマノイドの全身制御やその他の要素技術,社会実装にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
